Handling Nonlinearities with Gurobi 12
Gurobi Summit EMEAI 2024
The Decision Intelligence Summit
https://gurobi.github.io/slides/
LP and MIP
- Base problems that Gurobi solves
- Simplex and Barrier algorithms for LP
- Branch-and-cut for MIP
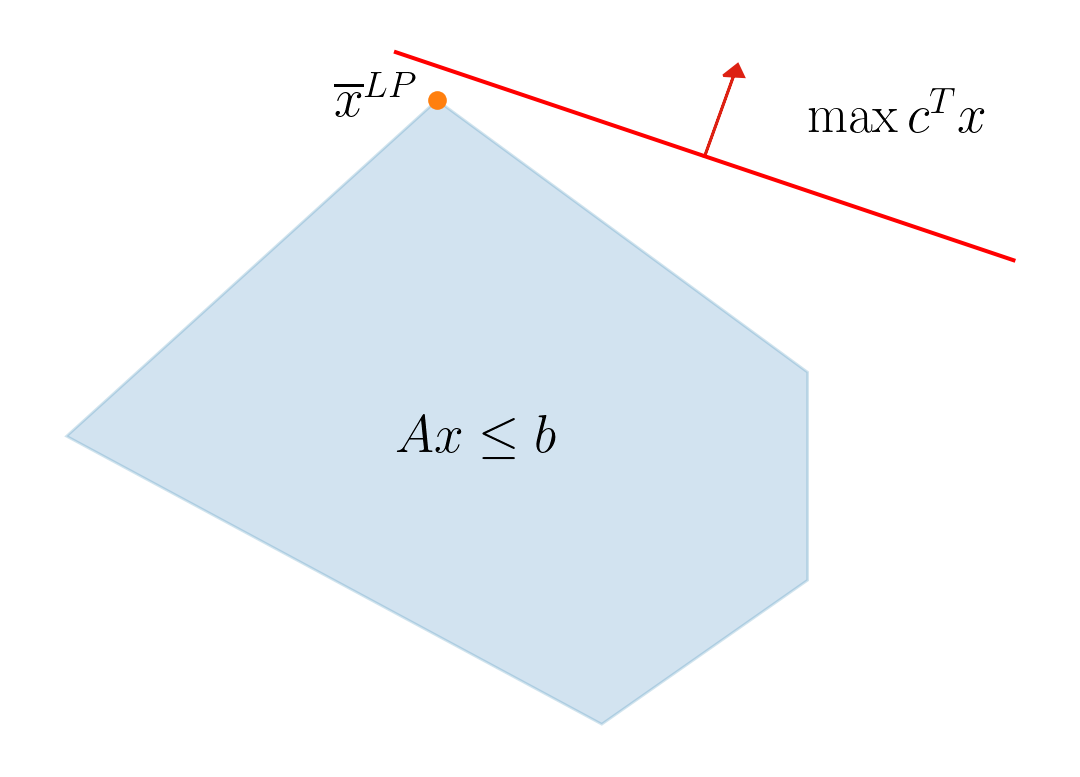
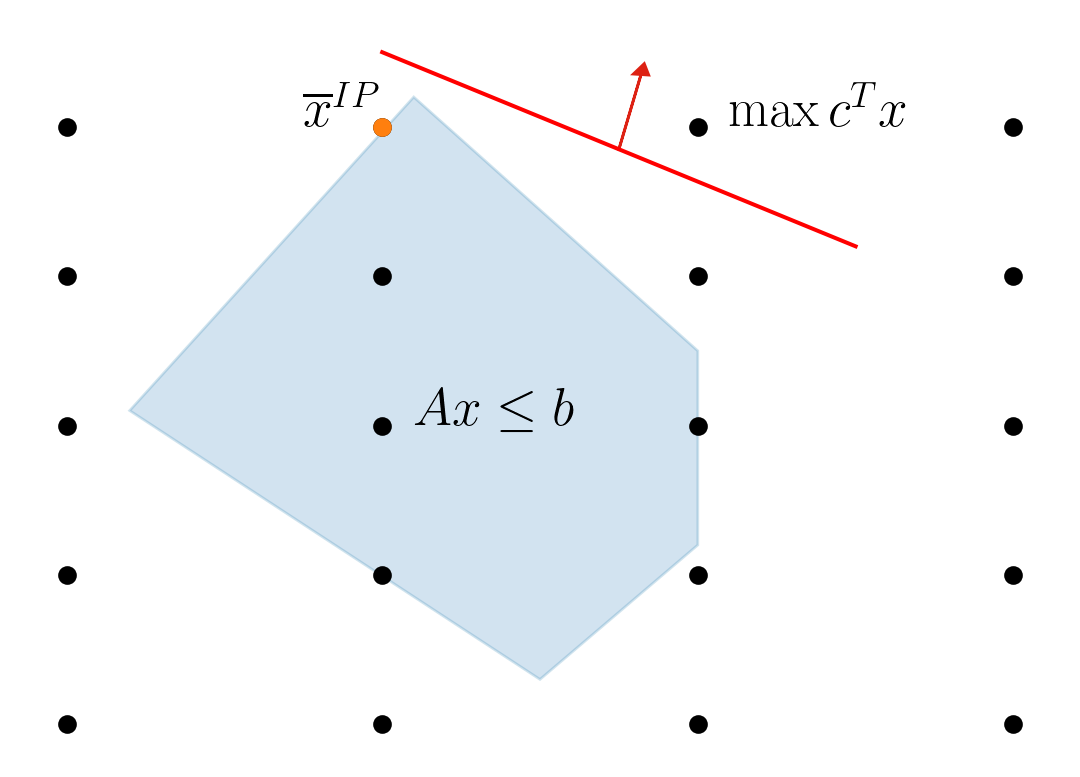
Convex or Not Convex?


Any segment connecting two points inside the region is inside the region.
There exists two points in the region the segment connecting them is not completely in the region.
Why?

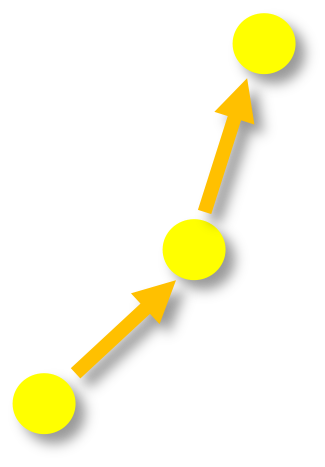
- Optimization “easy” (usually)
- Start from any point in the region
- Take steps inside the region improving objective
- When there is no more step global optimum
- Interior point methods for any closed convex region
- Simplex algorithm for polyhedra
- Optimization “hard”
- Start from any point in the region
- Take steps inside the region improving objective
- When there is no more step local optimum is reached
- Need a divide-and-conquer algorithm to find a global optimum.
The Second Order Cone
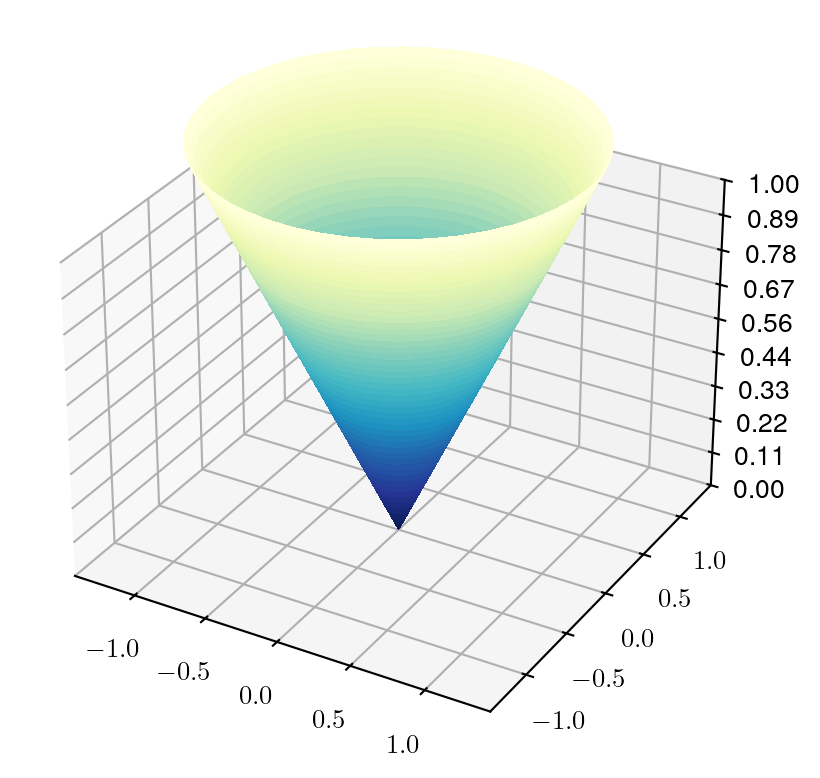
Through simple algebra, can be represented as SOC:
- \(\sum_{i=1}^n x_i^2 \le x_0^2\), with \(x_0\ge 0\)
- \(\sum_{i=2}^n x_i^2 \le x_0 x_1\), with \(x_0, x_1 \ge 0\) (rotated SOC)
- \(a^T x + x^T Q x \le b\), with \(Q \succeq 0\)
- \(x^T Q x \le y^2\), with \(Q \succeq 0, y \ge 0\)
Very powerful but modeling sometimes far from obvious.
Not all forms recognized by solvers
Note
Our barrier algorithm needs everything converted
to SOC or linear by presolve.
New in Gurobi 12
Barrier implicitly handles bounds on variables
The Outer Approximation Cut
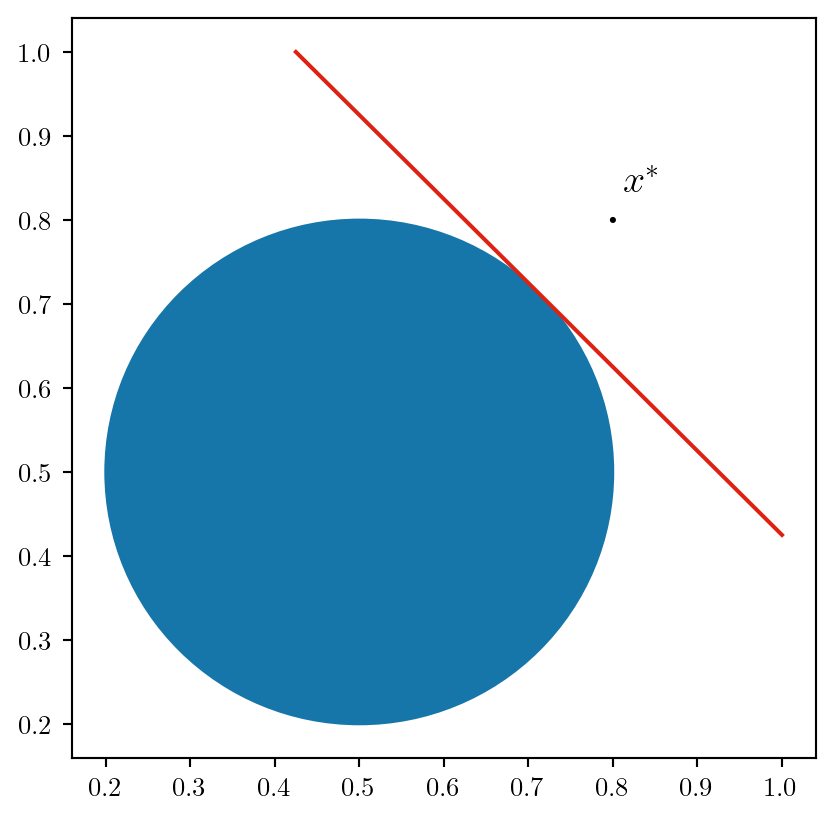
- Let \(C = \{g(x) \le b: x \in R^n\}\), with \(g\) a convex function
- For any \(x^* \in \mathbb R^n\), the constraint: \[\nabla g(x^*) (x - x^*) + g(x^*) \le 0 \] is valid
- If \(x^* \not \in C\), it cuts \(x^*\): \[ \nabla g(x^*) (x^* - x^*) + g(x^*) > 0 \]
Cone Disaggregation and Outer Approximation
An exponential number of cutting planes is needed to approximate a convex quadratic form.
Cone disaggregation
From \[ \sum_{i = 1}^n x_i^2 \le x_0^2, x_0 \ge 0 \]
- Create variables \(y_i \ge 0\), such that \(x_i^2 \le y_i x_0\) (rotated SOC)
- Replace initial constraint with \(\sum_{i = 1}^n y_i \le x_0\)
Stepping Into a Nonconvex World



Convex Envelopes: Parabola
Consider the square case: \(z = x^2\)
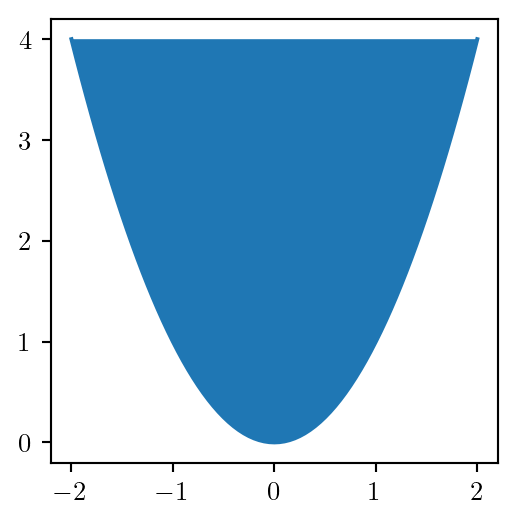
It is convex: \[ z^-(x_i, x_i) = x_i^2 \]
Can be dealt with by OA.
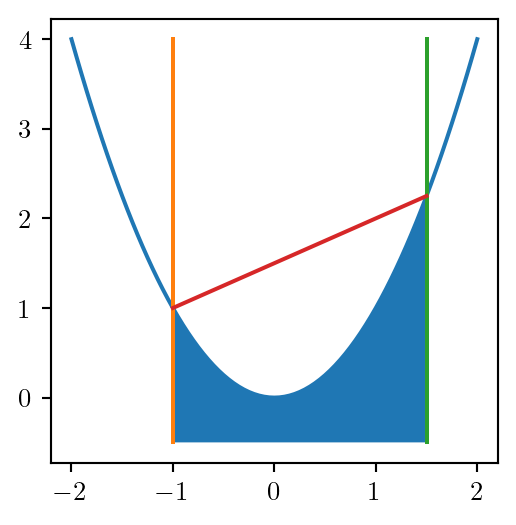
\(z^+(x_i, x_i)\) is given by the secant: \[ z^+_{ii} = (u + l) x_i - l \cdot u \]
Convex Envelopes: Products (McCormick)
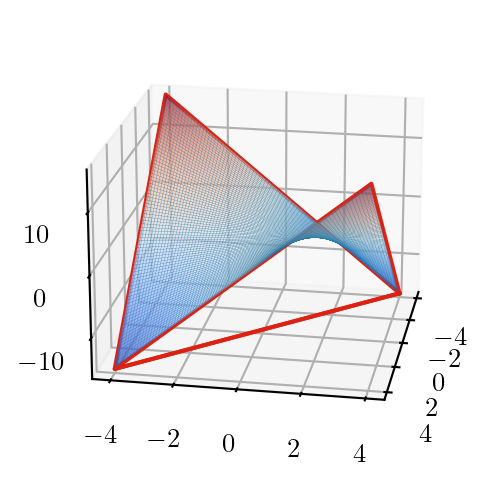
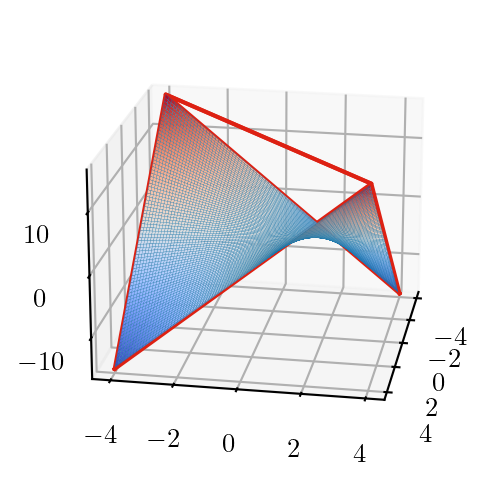
\[ z^-_{ij} = \max \left\{ \begin{aligned} & 𝑙_j x_i+ 𝑙_i 𝑥_j - 𝑙_i 𝑙_j \\ & 𝑢_j x_i + 𝑢_i x_j - u_i u_j \end{aligned} \right\} \le z_{ij} \le z^+_{ij} = \min \left\{ \begin{aligned} & 𝑙_j x_i+ u_i 𝑥_j - u_i l_j \\ & 𝑢_j x_i + l_i x_j - l_i u_j \end{aligned} \right\} \]
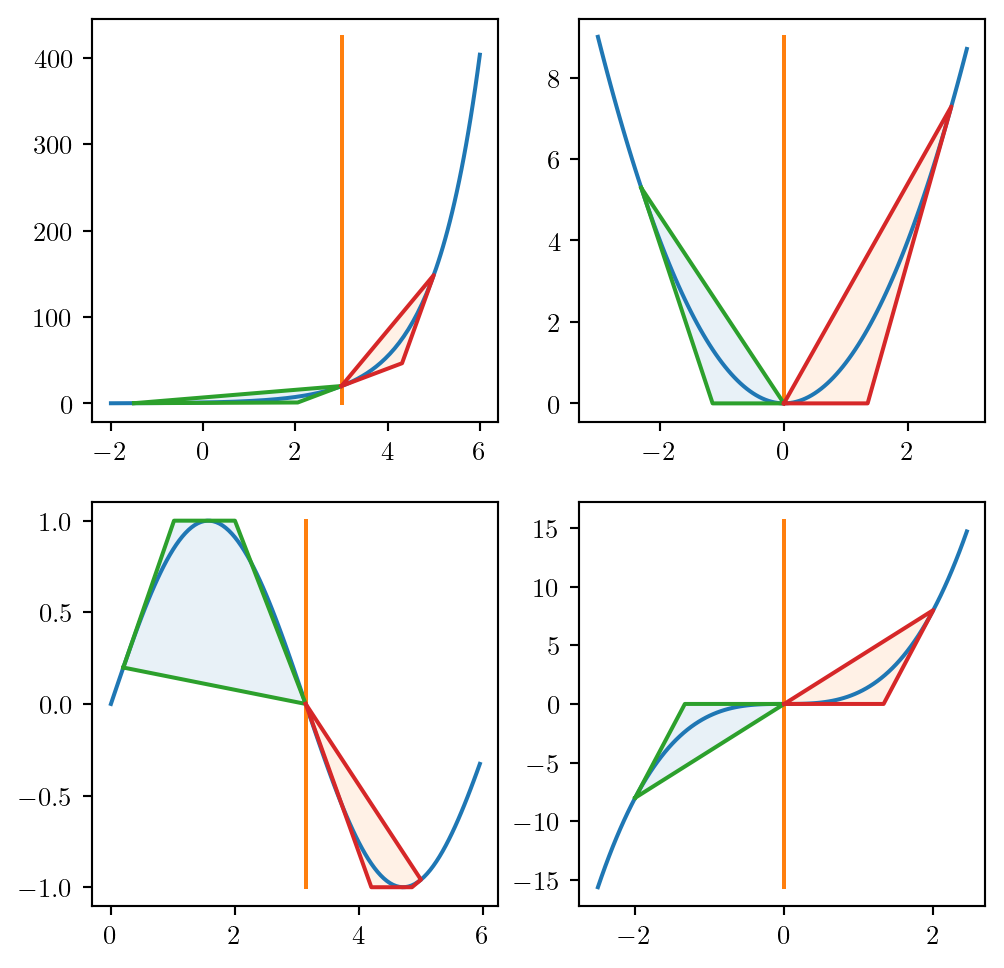
Spatial Branching
- Let \((x^*, z^*)\) be the solution of the bilinear relaxation
- If \(z^*_{ij} = x^*_i x^*_j\), for all bilinear terms: solution
- Otherwise refine our bilinear relaxation:
- Pick \(x_i\) or \(x_j\) s.t. \(z^*_{ij} \ne x^*_i x^*_j\)
- Create two child nodes with \(x_i \le x^*_i\) and \(x_i \ge x^*_i\)
- Refine bilinear relaxation in the two nodes
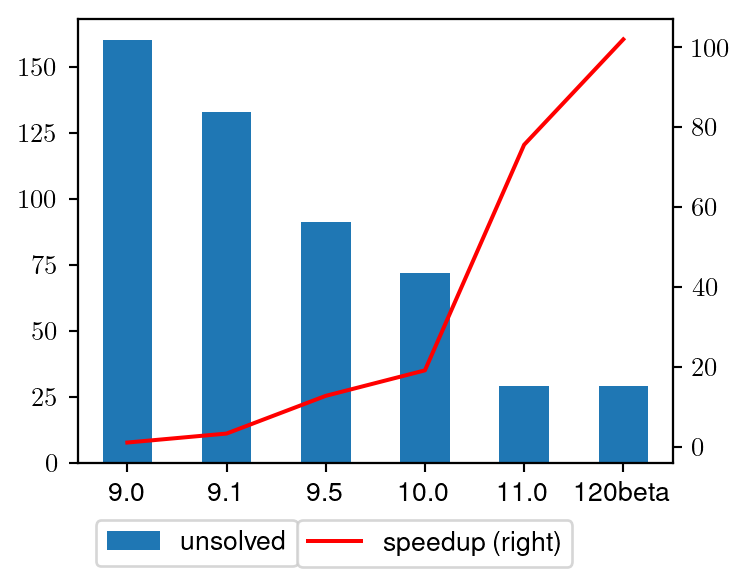
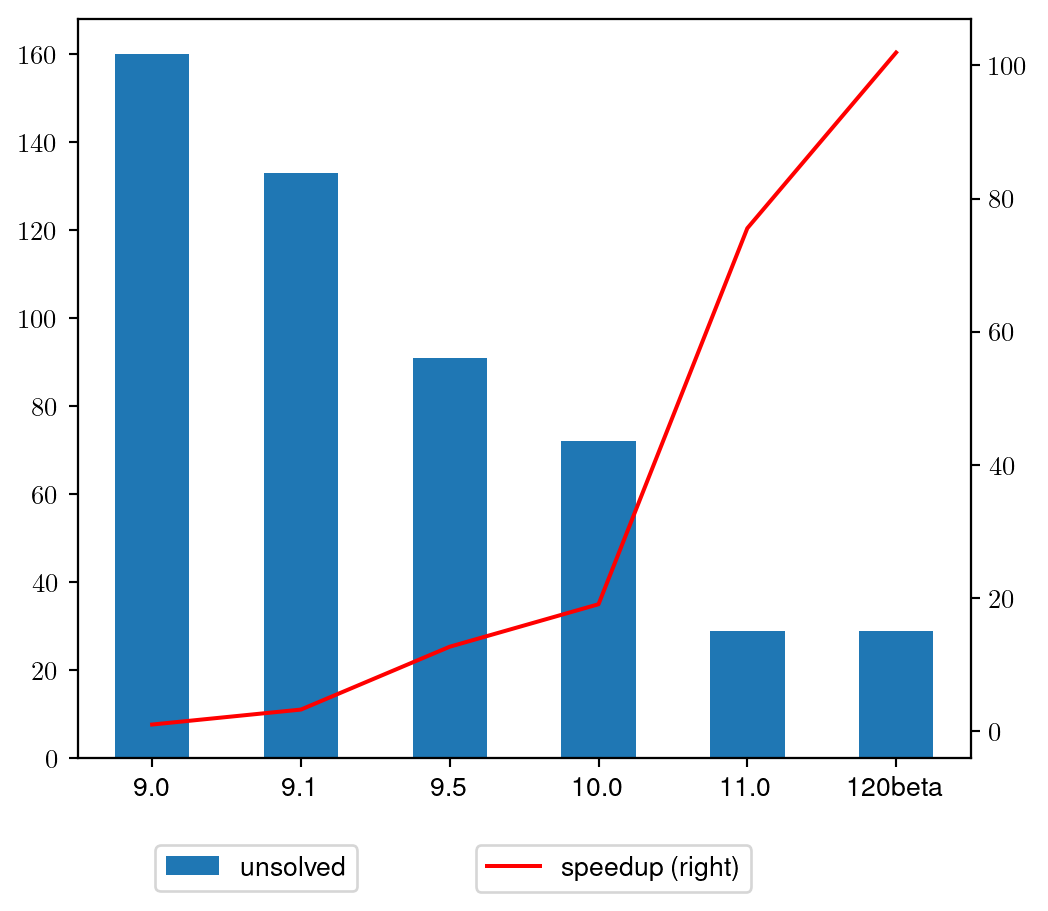
Nonconvex MIQCQP Performance History
New Nonlinear Constraints in Gurobi 12
- Support for constraints \(y = f(x)\)
- \(f: \mathbb R^n \rightarrow \mathbb R\)
- \(y\) is a Gurobi variable, \(x\) a vector of variables
- \(f\) may be composed of:
- arithmetic operations (\(+, -, \times, /\))
- a predefined list of univariate functions:
- \(\exp\), \(\log\), \(x^a\), \(b^x\), \(\sqrt x\)
- \(\sin\), \(\cos\), \(\tan\), \(\text{logistic}\)
- E.g. a valid function: \[ \begin{aligned} f(x) = & 3 \cdot (1-x_1)^2 \cdot \exp(-x_1^2 - (x_2+1)^2) - \\ & 10 \cdot (\frac{x_1}{5} - x_1^3 - x_2^5) \ldots \end{aligned} \]
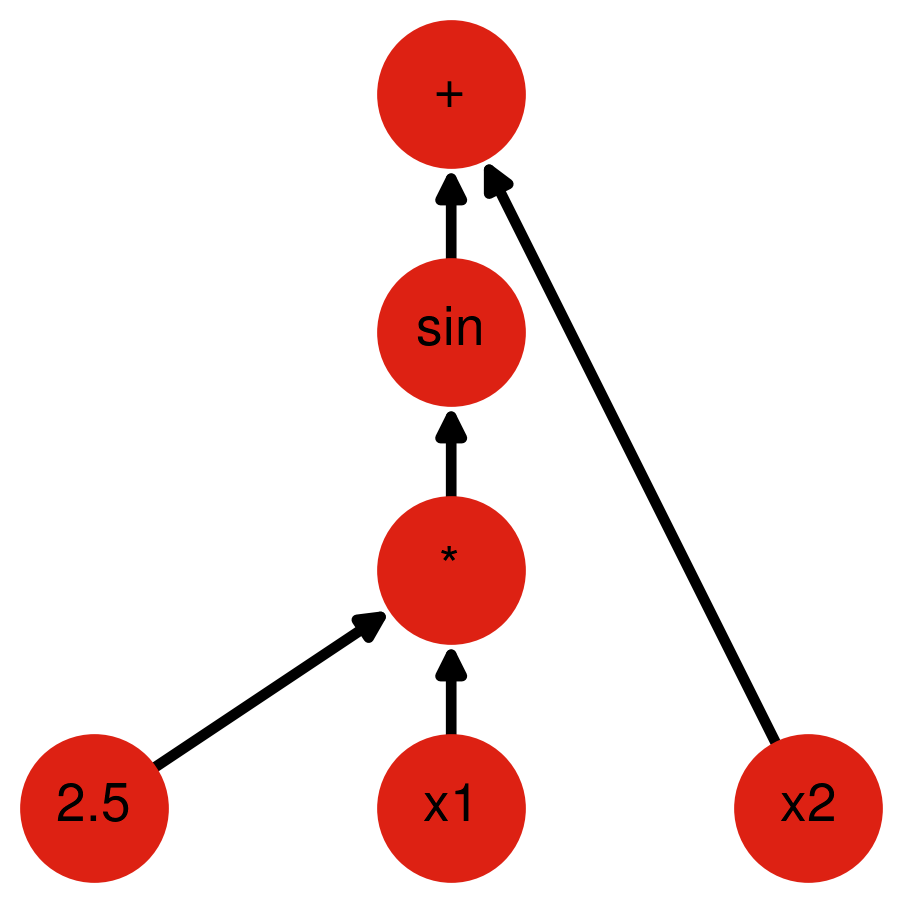
Expression Tree Representation
Internal representation of a nonlinear constraint:
- Leaves: variables or constants
- Internal nodes: operations on the children
- Root: result of expression
| index | opcode | data | parent |
|---|---|---|---|
| 0 | plus | -1 | -1 |
| 1 | sin | -1 | 0 |
| 2 | multiply | -1 | 1 |
| 3 | constant | 2.5 | 2 |
| 4 | variable | 1 | 2 |
| 5 | variable | 2 | 0 |
Warning
In non-Python API nonlinear constraints
are entered with this representation
Sketch of Solution Strategy
Similar to bilinear
Construct a disaggregated formulation
For each function, compute lower/upper envelope
Spatial branching to refine them
Additional difficulties:
- large values (\(\exp\))
- asymptotes (\(1/x\), \(\log\))
- periodic functions (\(\cos\),…)
A Training Example
\(\bar x\) is a grayscale image of \(28\times 28\) (\(=784\)) pixels
The output is a vector \(y\) of length 10 (each entry corresponding to a digit)
The image is classified according to the largest entry of \(y\)
The entries of the vector are computed using SoftMax and are probability estimates
Predicted label is 1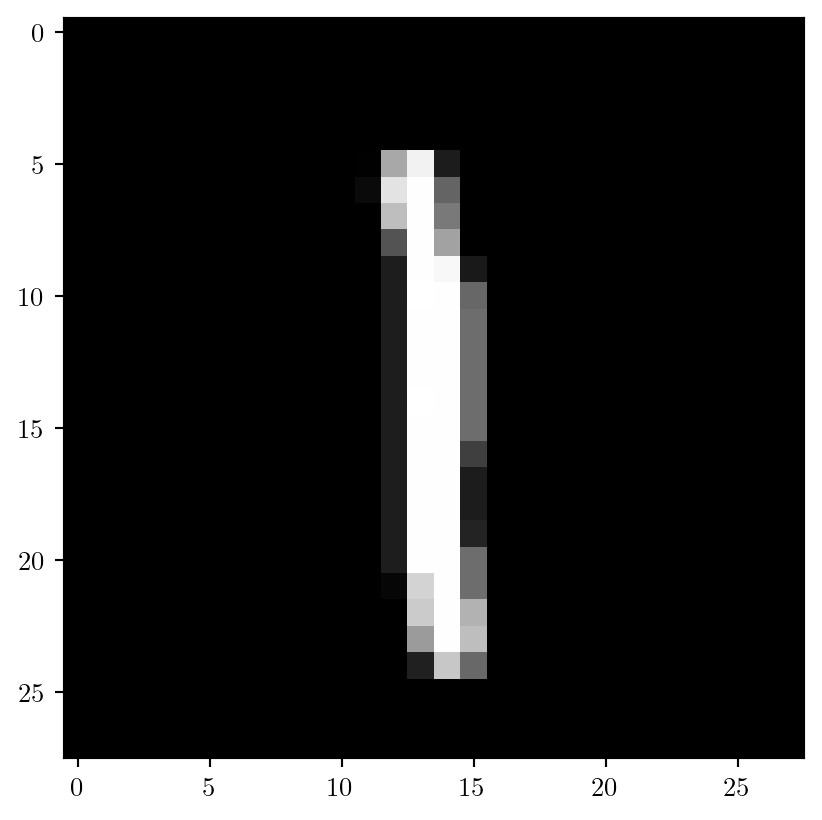
y = [0. 0.98 0. 0. 0. 0. 0. 0. 0.01 0. ]Solution
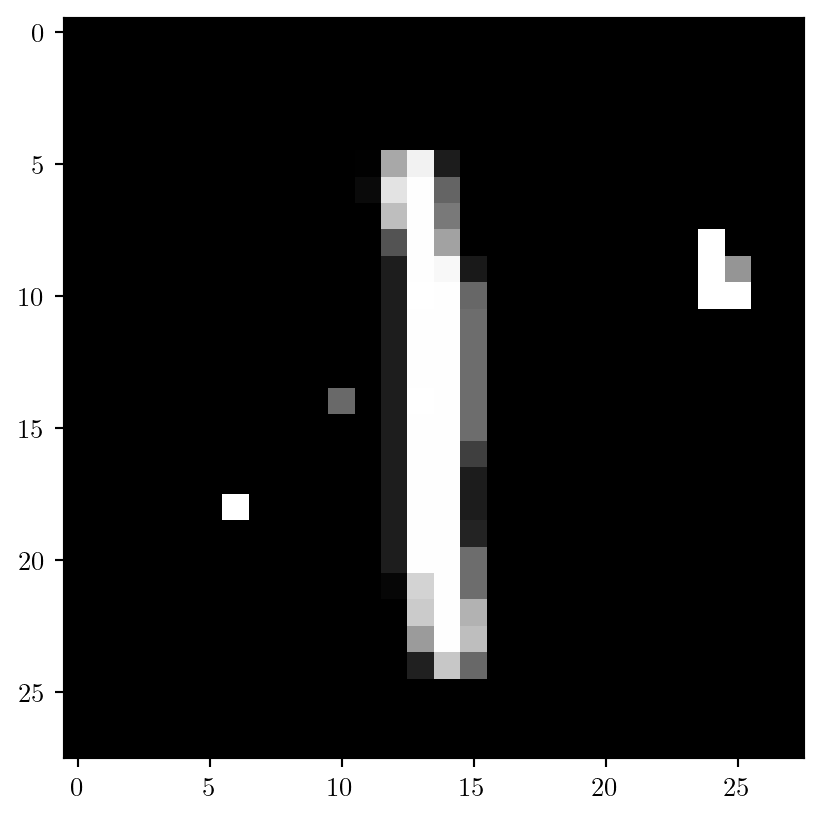
Label probabilites for perturbed image:
[0. 0.24 0. 0. 0. 0.74 0. 0. 0.01 0. ]Conclusions and Outlook
- (nonconvex) MIQCP solver state of the art, tremendous improvements
- Second iteration of MINLP solver:
- Real nonlinear constraints
- Improved stability and performance
- Current weaknesses and outlook
- Focus is on global optimality
- Nonlinear optimization capabilities for locally optimal solution
- Difficult to get high accuracy (\(< 10^{-5}\)) by branching only