The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!Gurobi in the Python Ecosystem
From GitHub Octoverse 2024…
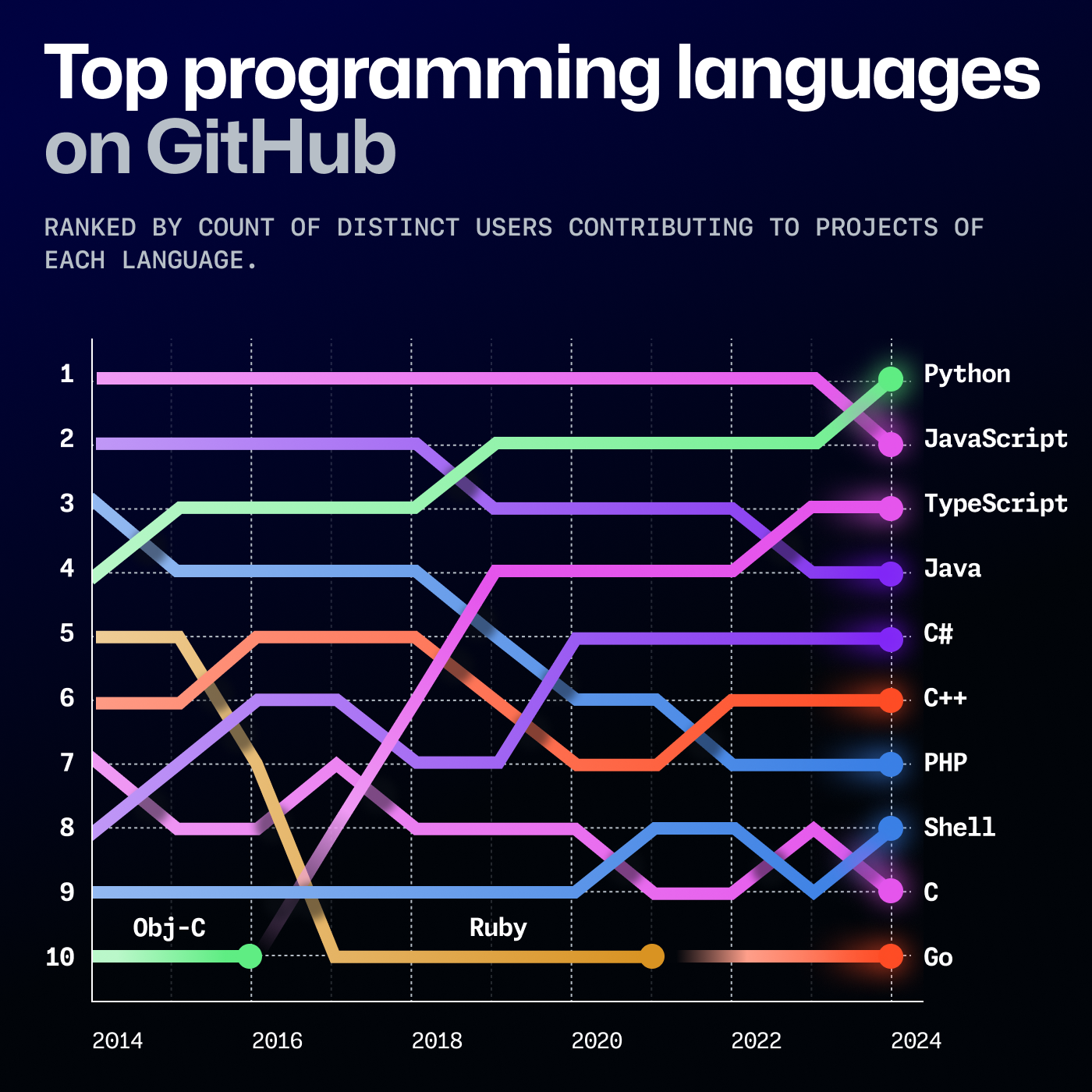
Source: https://github.blog/news-insights/octoverse/octoverse-2024/
PYPL – PopularitY of Programming Language
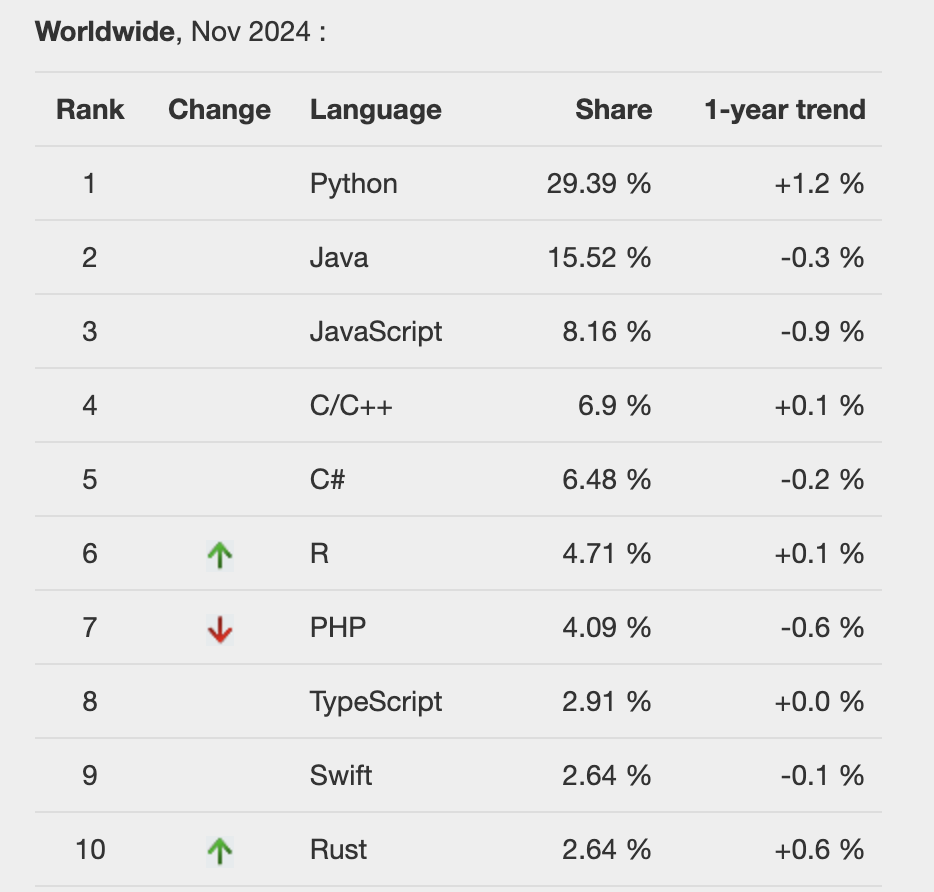
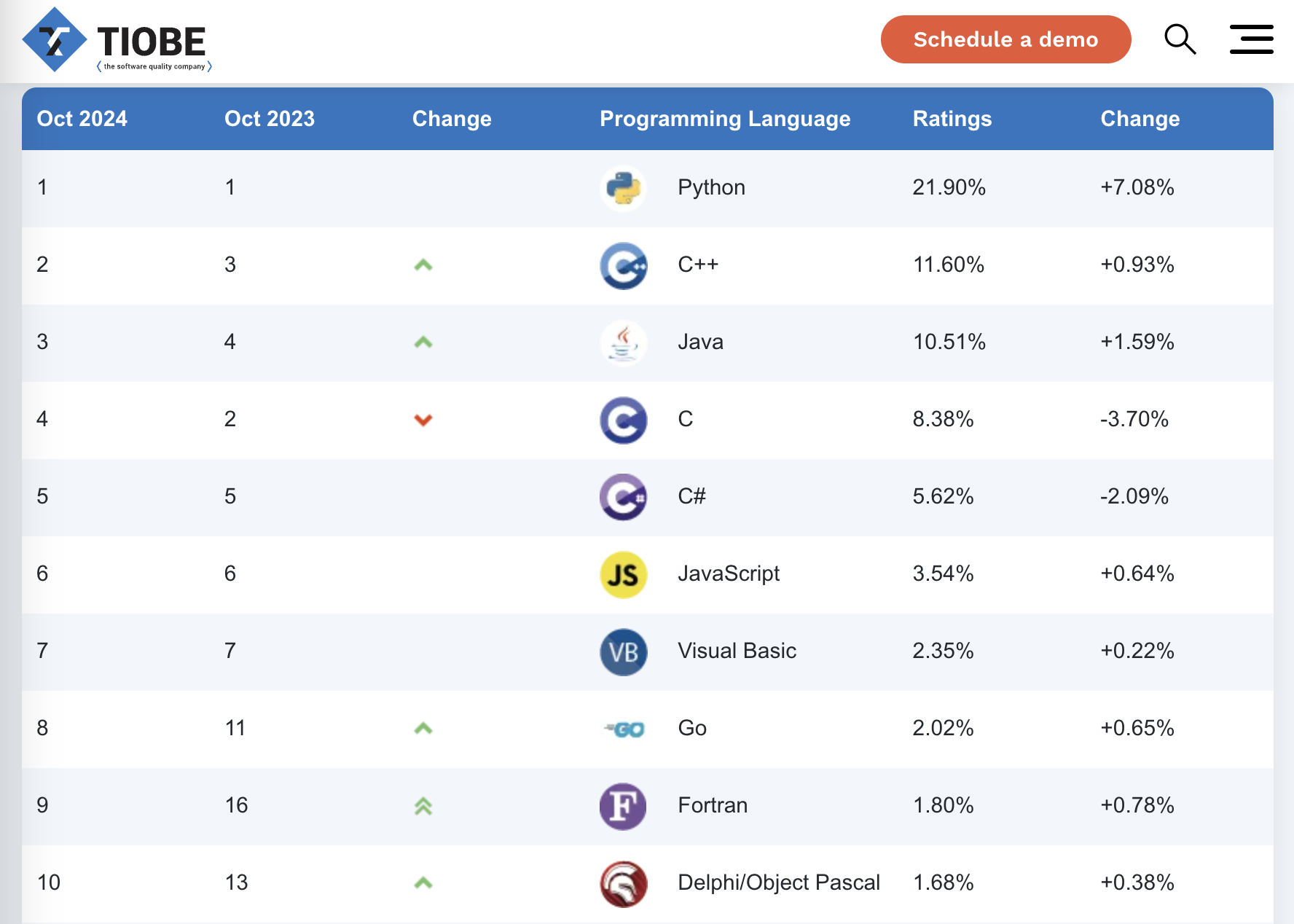
TIOBE
Gurobi has a heart for Python
gurobipy: Your pythonic and fast Gurobi API
gurobipy-pandas: Build optimization models directly out of data frames
gurobi-machinelearning: Incorporate trained regressors in optimization models
gurobi-modelanalyzer: Analyze and understand numerical aspects of your optimization model
gurobi-optimods: Data-driven APIs for common optimization tasks
![]()
Many projects hosted at https://github.com/Gurobi
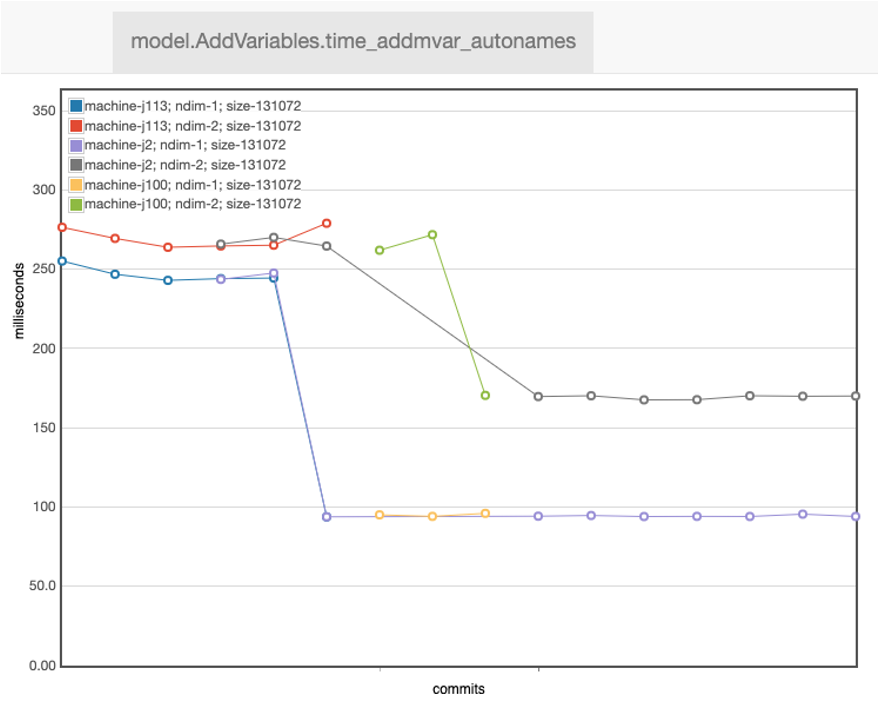
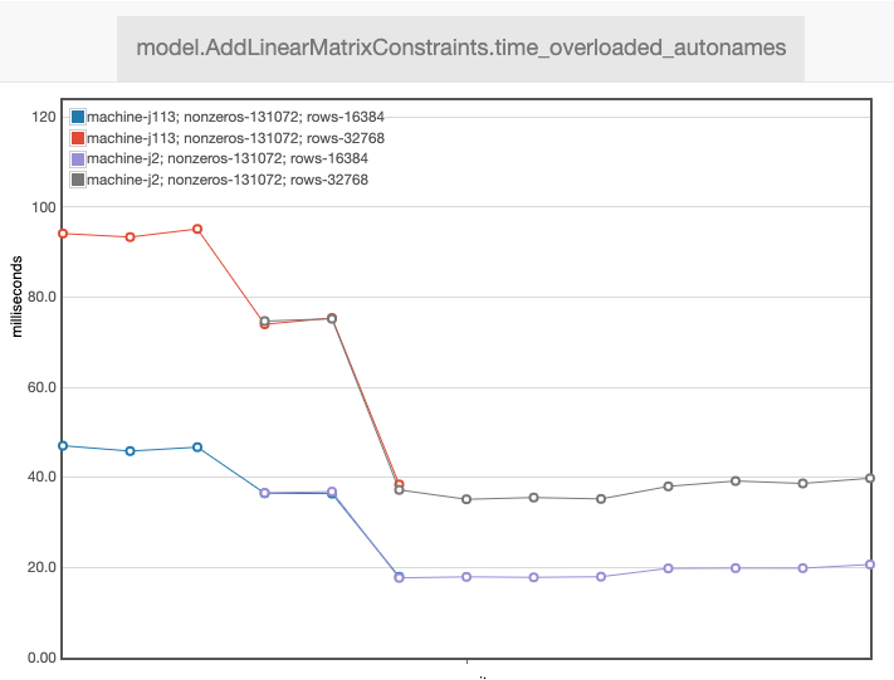
Modeling performance
- A lot of effort is spent on making gurobipy fast
- Automatic performance monitoring of common modelling patterns
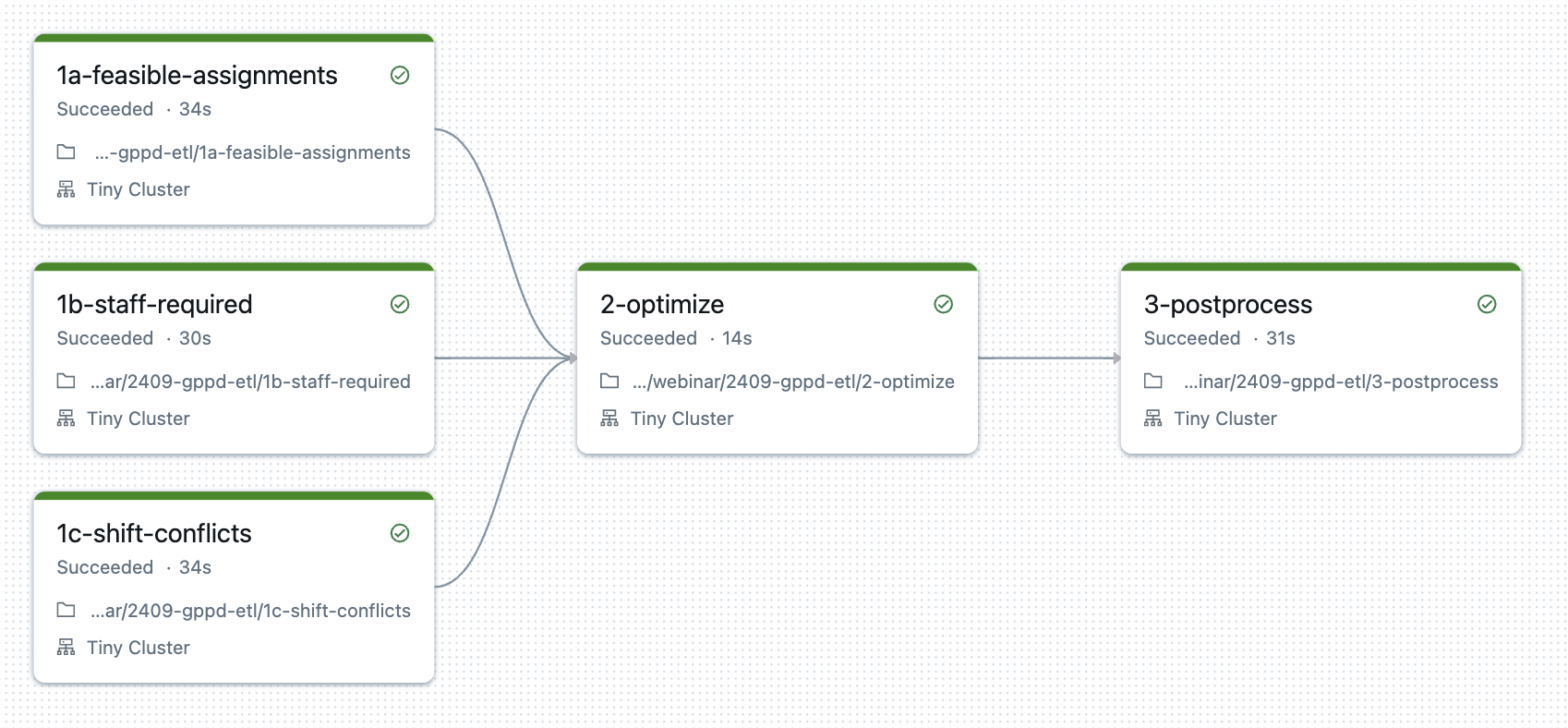
Typical Databricks workflow
Data-driven optimization models can (and should!) be integrated directly in your ETL pipelines
Solver deployment
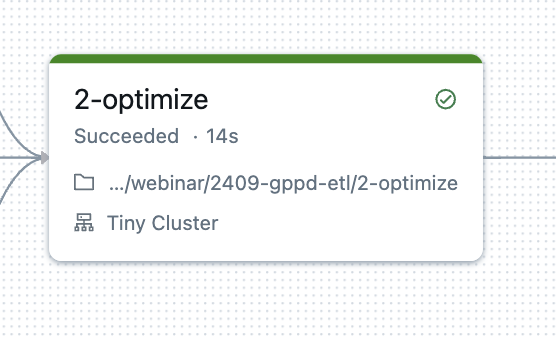
- Run locally (size-limited license)
- Run locally on the databricks cluster
- Run remotely using Gurobi Instant Cloud
- Run remotely on your own servers
Solving with Instant Cloud
Example: Adversarial ML
Given a trained network, how robust is the classification w.r.t. noise?
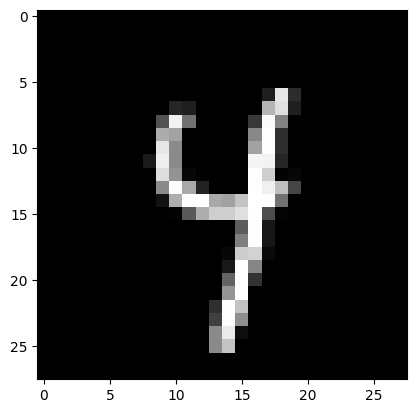
Classified as “4”
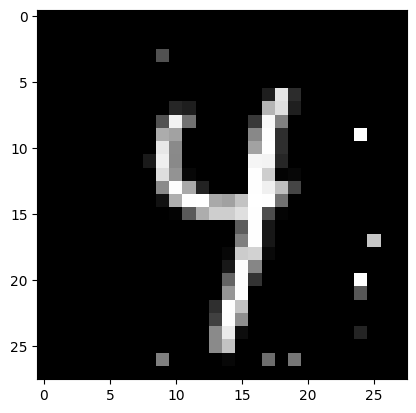
Classified as “9”
An OptiMod …
- Is a tool to solve a specific, practical problem
- Has a data-driven API for a common optimization problem
- Takes data in “natural” form, returns a solution in “natural” form
- Solves a mathematical optimization problem using Gurobi technology
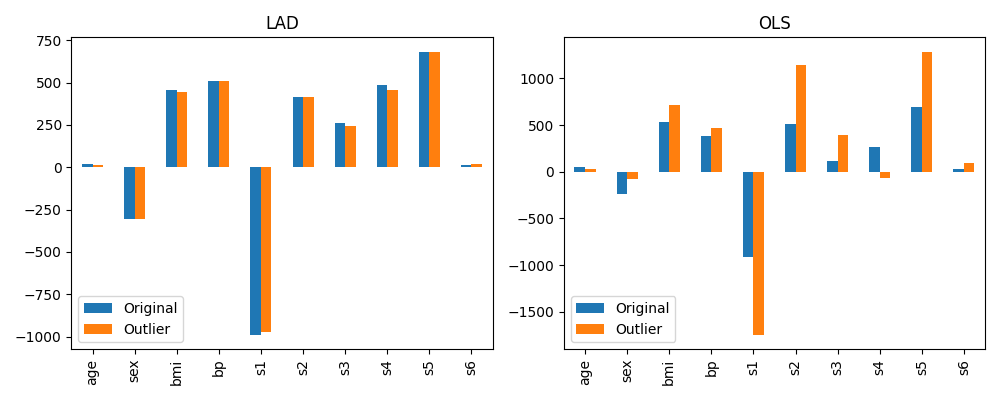
LAD is more robust than ordinary linear regression w.r.t. outliers
Takeaways
- Gurobi has a heart for Python
- Gain productivity from our provided tools
- https://github.com/Gurobi
![]()
![]()