Gurobi Performance on OET Benchmarks
Agenda
What are we going to cover?
What is the Gurobi Parameter Tuner?
How does the Tuner work?
How much performance can we gain?
How to evaluate benchmarks?
OET LP results
OET MIP results

Gurobi Parameter Tuning Tool
A quick overview
- Part of the standard Gurobi distribution (often referred to as the “Tuner”)
- Evoke from the command line using
grbtuneor call from the API
- Tries to find the best parameters within the given time limit
- Distributable over multiple machines to speed up the tuning process
- Heavily used by Gurobi Experts to tune customer models

Important things to consider
Some words of caution
- Tuning many models at the same time takes more time
- Tuning too many diverse models may not lead to good results
- Tuning few models can result in over-tuning → use more tune trials (seeds)
- Balance is important - the defaults have been tested on thousands of models

Evaluating and analyzing Gurobi runs
Using the open-source gurobi-logtools
- gurobi-logtools is a package to
- parse Gurobi logs into pandas DataFrames or Excel sheets
- aggregate results over multiple runs, models, or parameters
- visualize everything in an interactive way
- complement the tuner by allowing in-depth analytics
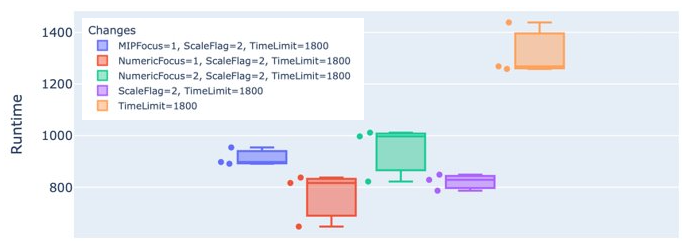
Gurobi on the OET LP instances
Apply tuned parameters to entire benchmark
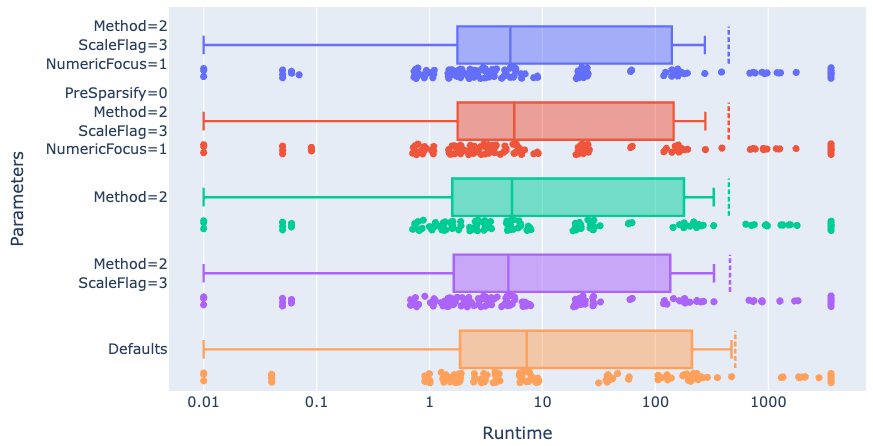
- only slight improvement on the whole test set (note the log-scale x-axis)
- models are too diverse to succeed with a single parameter set
Gurobi on the OET LP instances
Apply tuned parameters to entire benchmark
- only slight improvement on the whole test set (note the log-scale x-axis)
- models are too diverse to succeed with a single parameter set
This is actually a sign of a good benchmark!
Takeaways
Please feel free to ask any related questions
- Parameter tuning can expose hidden potential/performance in all solvers
- More effective than using more powerful hardware
- Tuning can be time-consuming and works best on distributed machines
- There are quite a few pitfalls:
- Watch out for numerical issues and inconsistent results
- Avoid over-tuning by regularly re-evaluating your settings and using seeds
- There likely are no perfect fixed settings for diverse sets of models
- The default values often choose automatically based on the specific model
- When analyzing aggregated results, do not neglect single model behaviors
- Improving your model formulation can be even more effective
Ask the Gurobi Experts for help when stuck or unsure how to start!
![]()